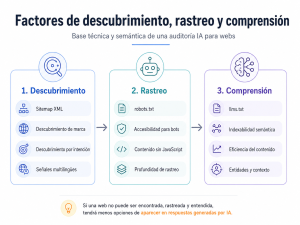
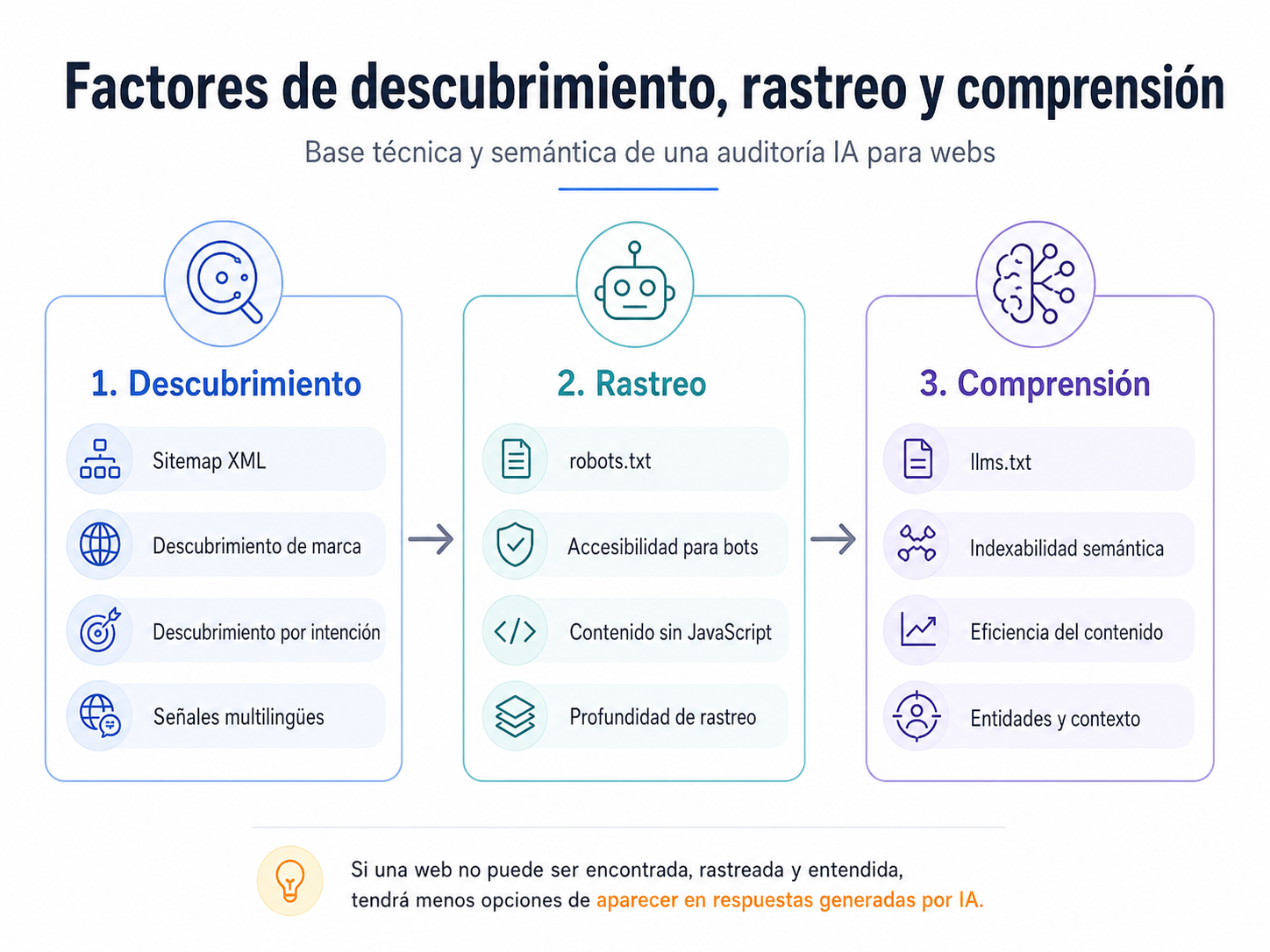
Factores de descubrimiento, rastreo y comprensión en Auditorias IA para Webs

En una edición pasada, hablamos de como auditar una web para salir en herramientas IA, y en esta oportunidad hablaremos de los factores de descubrimiento, rastreo y comprensión son la base de cualquier auditoría IA para webs, porque determinan si una página puede ser encontrada, leída e interpretada correctamente por buscadores, modelos de lenguaje y agentes de inteligencia artificial. Antes de evaluar la autoridad, la confianza o la capacidad de integración de una web, es necesario comprobar que sus contenidos son accesibles, que no existen bloqueos técnicos innecesarios, que la arquitectura facilita el rastreo y que los sistemas automatizados pueden entender qué ofrece el sitio.
- 1. Descubrimiento directo de marca en IA
- 2. Descubrimiento por caso de uso o intención
- 3. Existencia de sitemap XML
- 4. Contenido accesible sin JavaScript
- 5. Accesibilidad para bots y agentes de IA
- 6. Política de IA en robots.txt
- 7. Diferenciación de crawlers de IA
- 8. Existencia de llms.txt
- 9. Calidad del llms.txt
- 10. Existencia de llms-full.txt
- 11. Archivos de instrucciones para agentes
- 12. Agent discovery file
- 13. A2A Agent Card
- 14. Presencia en registros MCP
- 15. Paquetes SDK en NPM o PyPI
- 16. Configuraciones para plataformas de agentes
- 17. Presencia en skills.sh
- 18. pricing.md
- 19. NLWeb Schema Feeds
- 20. Descubrimiento MCP well-known
- 21. Vista específica para agentes
- 22. Etiquetado visual de contenido
- 23. Señales multilingües y hreflang
- 24. Eficiencia de contenido
- 25. Señales de profundidad de rastreo
- 26. HTTP Link headers
- 27. Fallback Markdown /index.md
- 28. llms.txt modular por área
- 29. Simulación de rastreo multiagente
- 30. Indexabilidad semántica
- 31. Autoridad de marca en datos y fuentes externas
- 32. Context window efficiency
- Resumen de Factores de descubrimiento, rastreo y comprensión en Auditorias IA para Webs
En este bloque se revisan elementos como el sitemap XML, el archivo robots.txt, la accesibilidad sin JavaScript, los archivos llms.txt, la indexabilidad semántica, las señales multilingües, la eficiencia del contenido y la profundidad de rastreo.
Sin esta base, una web puede tener buen contenido o una propuesta de valor sólida, pero tendrá muchas menos posibilidades de aparecer en respuestas generadas por IA, recomendaciones conversacionales o entornos de búsqueda impulsados por inteligencia artificial.
Entremos en materia.
1. Descubrimiento directo de marca en IA
Qué es
El descubrimiento directo de marca analiza si una web puede ser encontrada cuando un usuario, buscador o asistente de IA busca directamente el nombre de la empresa, marca o dominio.
Por qué revisarlo
Los sistemas de IA necesitan reconocer entidades. Si una marca no tiene señales claras, puede ser confundida con otra, descrita de forma incompleta o ignorada en una respuesta.
Cómo medirlo
Se revisa si la marca aparece en buscadores, asistentes conversacionales, perfiles sociales, directorios, medios, plataformas profesionales y otras fuentes externas. También se analiza si la web oficial ofrece información corporativa clara: quién es la empresa, qué hace, dónde opera y qué servicios ofrece.
Cómo optimizarlo
Para mejorar este punto conviene reforzar la presencia de marca en el ecosistema digital: crear o mejorar la página “Sobre nosotros”, mantener perfiles corporativos actualizados, conseguir menciones externas, unificar la descripción de la marca en todos los canales, publicar casos de éxito y trabajar señales de entidad mediante datos estructurados.
Por qué es importante
Una marca reconocible tiene más posibilidades de ser citada, recomendada y descrita correctamente por sistemas de IA. El descubrimiento directo es una señal básica de autoridad e identidad digital.
2. Descubrimiento por caso de uso o intención
Qué es
Este factor analiza si una web puede aparecer cuando el usuario no busca una marca concreta, sino una necesidad, problema o solución. Por ejemplo: “mejor agencia SEO para ecommerce”, “consultoría de analítica web” o “empresa para automatizaciones con IA”.
Por qué revisarlo
Gran parte de las consultas en IA son conversacionales y orientadas a problemas. Los usuarios suelen pedir recomendaciones, comparativas o soluciones concretas.
Cómo medirlo
Se revisa si la web tiene páginas posicionadas para servicios, sectores, problemas, necesidades o casos de uso. También se analiza si los contenidos utilizan un lenguaje alineado con la intención real del usuario.
Cómo optimizarlo
Se puede optimizar creando páginas específicas por servicio, sector, solución o necesidad. También ayudan las guías comparativas, las páginas de metodología, las FAQs y los casos de éxito.
Por qué es importante
Los sistemas de IA recomiendan soluciones basándose en la intención del usuario. Si la web no está conectada semánticamente con esas necesidades, tendrá menos posibilidades de aparecer en respuestas generativas.
3. Existencia de sitemap XML
Qué es
El sitemap XML es un archivo que lista las URLs principales de una web para facilitar su descubrimiento por parte de buscadores, rastreadores y sistemas automatizados.
Por qué revisarlo
Una web puede tener contenido importante que no esté bien enlazado internamente. El sitemap ayuda a declarar qué URLs deben ser descubiertas.
Cómo medirlo
Se comprueba si existe un archivo accesible, normalmente en /sitemap.xml. También se revisa si el XML es válido, si contiene URLs correctas y si no incluye páginas con errores, redirecciones o etiquetas noindex.
Cómo optimizarlo
El sitemap debe estar limpio, actualizado y alineado con la estrategia de indexación. Debe incluir solo URLs relevantes e indexables. En webs grandes, puede organizarse por tipo de contenido: páginas, artículos, productos, categorías, imágenes o vídeos.
Por qué es importante
Aunque el sitemap no garantiza la indexación ni la presencia en IA, facilita el rastreo y ayuda a los sistemas a descubrir la estructura principal de la web.
4. Contenido accesible sin JavaScript
Qué es
Este factor analiza si el contenido principal de una página puede leerse sin ejecutar JavaScript.
Por qué revisarlo
Muchas webs modernas cargan parte del contenido mediante scripts. Esto puede dificultar el rastreo si determinados bots o agentes no renderizan la página como un navegador completo.
Cómo medirlo
Se compara el HTML inicial de la página con la versión renderizada. Hay que comprobar si el HTML contiene los elementos principales: H1, H2, textos de servicio, enlaces internos, FAQs, CTAs, información corporativa y contenido principal de la página.
Cómo optimizarlo
Lo recomendable es que el contenido estratégico esté disponible en el HTML inicial o mediante renderizado del lado del servidor. También conviene evitar que los enlaces internos, textos clave o encabezados dependan exclusivamente de JavaScript.
Por qué es importante
Si el contenido no está disponible para determinados rastreadores, la web puede perder capacidad de indexación, comprensión semántica y presencia en respuestas generadas por IA.
5. Accesibilidad para bots y agentes de IA
Qué es
Este factor revisa si la web permite el acceso a rastreadores legítimos, bots de buscadores y agentes relacionados con sistemas de inteligencia artificial.
Por qué revisarlo
Una web puede estar técnicamente publicada, pero bloquear por error a ciertos bots mediante firewall, CDN, reglas de seguridad o configuración de servidor.
Cómo medirlo
Se revisan las respuestas que ofrece el sitio ante diferentes user-agents. También se analizan posibles errores HTTP como 403, 401, 429, bloqueos por firewall, bloqueos por CDN o bloqueos por robots.txt.
Cómo optimizarlo
La optimización depende de la estrategia de cada empresa. Si se busca ganar visibilidad en IA, conviene permitir el acceso a rastreadores relevantes y evitar bloqueos accidentales. También es recomendable diferenciar entre bots legítimos, bots de entrenamiento, bots desconocidos y tráfico automatizado abusivo.
Por qué es importante
Si un agente no puede acceder a una web, no puede leerla, interpretarla ni recomendarla. La accesibilidad para bots es una condición básica para la visibilidad en entornos de IA.
6. Política de IA en robots.txt
Qué es
El archivo robots.txt indica a los rastreadores qué partes de una web pueden o no pueden solicitar. En una auditoría IA, se revisa si existe una política clara para crawlers relacionados con inteligencia artificial.
Por qué revisarlo
Muchas empresas tienen configuraciones heredadas que no diferencian entre buscadores tradicionales, asistentes de IA, bots de entrenamiento y otros agentes automatizados.
Cómo medirlo
Se analiza el archivo /robots.txt y se revisa si contiene directivas específicas para bots de IA, si bloquea recursos importantes o si declara correctamente el sitemap.
Cómo optimizarlo
La empresa debe decidir qué bots quiere permitir, limitar o bloquear. Esta decisión debe estar alineada con su estrategia de visibilidad, protección de contenido y captación orgánica.
Por qué es importante
El robots.txt es una señal técnica y estratégica. Una mala configuración puede limitar la visibilidad de la web en buscadores, asistentes y sistemas de recuperación de información.
7. Diferenciación de crawlers de IA
Qué es
Este factor consiste en tratar de forma distinta a diferentes tipos de crawlers de IA según su función. Algunos rastrean contenido para motores de búsqueda, otros para asistentes, otros para entrenamiento de modelos y otros para análisis automatizado.
Por qué revisarlo
Una política única para todos los bots puede ser demasiado restrictiva o demasiado permisiva.
Cómo medirlo
Se analiza si el robots.txt diferencia entre distintos user-agents relacionados con IA y si existe una política específica para cada uno.
Cómo optimizarlo
Se puede definir una política por grupos: bots de buscadores, bots de asistentes, bots de entrenamiento, bots no deseados y bots desconocidos. La configuración debe revisarse con criterio técnico y legal.
Por qué es importante
Permite equilibrar visibilidad y control. Una empresa puede querer aparecer en asistentes de IA, pero limitar determinados usos de entrenamiento o rastreo masivo.
8. Existencia de llms.txt
Qué es
El archivo llms.txt es un archivo pensado para ofrecer a los modelos de lenguaje una guía estructurada sobre el contenido principal de una web.
Por qué revisarlo
Los modelos de lenguaje necesitan información clara y sintetizada. Una web puede tener muchas páginas, pero no siempre es evidente qué contenidos son más relevantes.
Cómo medirlo
Se comprueba si existe el archivo en rutas como /llms.txt o /.well-known/llms.txt. También se revisa si es accesible, legible y está correctamente estructurado.
Cómo optimizarlo
Un buen llms.txt debería incluir descripción de la empresa, servicios o productos principales, URLs clave, casos de uso, sectores, páginas de confianza, contenidos recomendados, información de contacto e instrucciones básicas para agentes.
Por qué es importante
Ayuda a los sistemas de IA a entender la web de forma más rápida y ordenada. No sustituye al SEO tradicional, pero añade una capa útil de contexto para modelos de lenguaje.
9. Calidad del llms.txt
Qué es
La calidad del llms.txt analiza si el archivo aporta información realmente útil o si se limita a una lista básica de enlaces.
Por qué revisarlo
Tener el archivo no garantiza que sea útil para IA. Un llms.txt mal planteado puede cumplir técnicamente, pero no mejorar la comprensión de la web.
Cómo medirlo
Se revisan la claridad de las secciones, la profundidad de la información, los enlaces incluidos, la cobertura de servicios, la descripción de la entidad, la información de contacto, el contexto para recomendación y la actualización del contenido.
Cómo optimizarlo
Se recomienda estructurarlo en Markdown con apartados claros: quiénes somos, servicios principales, casos de uso, sectores, diferenciales, URLs clave, preguntas frecuentes y contacto. El objetivo es facilitar comprensión, no repetir una landing promocional.
Por qué es importante
Un llms.txt bien construido puede mejorar la interpretación de la web por parte de sistemas de IA y reducir el riesgo de respuestas imprecisas.
10. Existencia de llms-full.txt
Qué es
llms-full.txt es una versión ampliada del archivo llms.txt. Su objetivo es proporcionar más contexto en un único documento legible por modelos de lenguaje.
Por qué revisarlo
Algunos agentes pueden beneficiarse de una versión más completa, especialmente si la web tiene muchos servicios, contenidos, sectores o páginas estratégicas.
Cómo medirlo
Se comprueba si existe en rutas como /llms-full.txt o /.well-known/llms-full.txt, y se analiza si incluye información más extensa que el llms.txt.
Cómo optimizarlo
Puede incluir descripción ampliada de la empresa, servicios detallados, metodología, casos de éxito, equipo, sectores, preguntas frecuentes, contenidos destacados, información comercial y páginas prioritarias.
Por qué es importante
Permite condensar el conocimiento principal de una web en un recurso único. Esto facilita que un agente obtenga contexto profundo sin tener que navegar por múltiples URLs.
11. Archivos de instrucciones para agentes
Qué es
Los archivos de instrucciones para agentes son documentos que explican cómo debe interpretarse una web por parte de sistemas automatizados. Un ejemplo posible sería /agents.md.
Por qué revisarlo
Un agente puede necesitar información más específica que un usuario humano: qué páginas consultar, cuándo recomendar un servicio, qué limitaciones existen o cómo debe interpretar la propuesta de valor.
Cómo medirlo
Se revisa si existen archivos de instrucciones para agentes y si contienen información útil, actualizada y estructurada.
Cómo optimizarlo
Un archivo para agentes puede incluir qué hace la empresa, qué servicios ofrece, en qué casos debe recomendarse, en qué casos no encaja, qué URLs son prioritarias, qué datos debe solicitar al usuario, cómo iniciar el contacto y qué información no debe asumir.
Por qué es importante
Reduce ambigüedad y puede ayudar a que las recomendaciones de los agentes sean más precisas, especialmente en webs con servicios complejos.
12. Agent discovery file
Qué es
Un archivo de descubrimiento para agentes permite que sistemas automatizados localicen recursos, instrucciones o capacidades asociadas a una web.
Por qué revisarlo
Los agentes necesitan mecanismos de descubrimiento claros. Si no existen, deben inferir la información navegando por la web, lo que puede generar errores o interpretaciones parciales.
Cómo medirlo
Se revisa si existen rutas como /agents.md, /.well-known/agent-skills o /skills.sh, y si estos archivos describen recursos, capacidades o instrucciones.
Cómo optimizarlo
Se puede crear un archivo de descubrimiento con enlaces a llms.txt, llms-full.txt, páginas de servicio, FAQs, contacto, documentación e instrucciones para agentes.
Por qué es importante
Facilita que los agentes identifiquen rápidamente qué recursos existen y cómo deben utilizarlos.
13. A2A Agent Card
Qué es
Una A2A Agent Card es una tarjeta en formato JSON pensada para describir las capacidades de un agente o servicio agentic.
Por qué revisarlo
Si una empresa ofrece un agente propio, una herramienta automatizable o una integración, necesita una forma estructurada de describirla.
Cómo medirlo
Se comprueba si existe un archivo en una ruta como /.well-known/agent-card.json y si contiene una estructura válida.
Cómo optimizarlo
Solo debe implementarse si existe un agente o servicio técnico real. En ese caso, el archivo debe describir nombre del agente, descripción, capacidades, URL de acceso, métodos soportados, requisitos de autenticación y limitaciones.
Por qué es importante
Es relevante para productos agentic y herramientas conectables. Para una web corporativa sin agente propio, normalmente no es prioritario.
14. Presencia en registros MCP
Qué es
Este factor analiza si una empresa o producto aparece en registros o directorios de servidores MCP. MCP permite conectar aplicaciones de IA con herramientas, fuentes de datos o sistemas externos.
Por qué revisarlo
Si una empresa ofrece una herramienta técnica o integración, estar presente en registros MCP puede facilitar su descubrimiento por agentes y desarrolladores.
Cómo medirlo
Se revisa si el dominio, producto o marca aparece en directorios MCP relevantes.
Cómo optimizarlo
Solo aplica si existe un servidor MCP. En ese caso, se debe crear el servidor, documentar sus herramientas, publicarlo en registros relevantes, mantener una descripción clara y definir autenticación y permisos si aplica.
Por qué es importante
Para productos técnicos, mejora el descubrimiento y la adopción por agentes. Para una web de servicios sin API, suele ser un factor avanzado o no aplicable.
15. Paquetes SDK en NPM o PyPI
Qué es
Este factor analiza si existe un paquete técnico asociado a la marca en registros como NPM o PyPI. Los SDKs permiten que desarrolladores integren una API o servicio de forma más sencilla.
Por qué revisarlo
En productos digitales, una buena adopción técnica depende de que los desarrolladores puedan usar la herramienta con facilidad.
Cómo medirlo
Se busca si existen paquetes oficiales vinculados al nombre de la empresa, dominio o producto.
Cómo optimizarlo
Si la empresa tiene API o herramienta técnica, puede crear SDKs bien documentados para los lenguajes más relevantes. Deben incluir instalación, ejemplos, autenticación, métodos principales, versionado, mantenimiento y repositorio oficial.
Por qué es importante
Es un factor clave para plataformas técnicas, pero no para todas las webs. En una auditoría IA debe clasificarse como aplicable solo si la empresa ofrece un producto programático.
16. Configuraciones para plataformas de agentes
Qué es
Este factor revisa si existen archivos de configuración o instrucciones para herramientas de IA y entornos de desarrollo asistido, como Cursor, Claude, Windsurf u otros.
Por qué revisarlo
Algunas empresas técnicas pueden facilitar el uso de sus productos mediante reglas, instrucciones o configuraciones adaptadas a agentes de desarrollo.
Cómo medirlo
Se buscan repositorios, carpetas o archivos relacionados con plataformas agentic, por ejemplo .cursor/, /.claude/ o /.windsurf/.
Cómo optimizarlo
Solo aplica en productos técnicos. La optimización consiste en publicar instrucciones claras para que los agentes usen correctamente una librería, API, framework o herramienta.
Por qué es importante
Puede mejorar la experiencia de desarrolladores que trabajan con asistentes de código. Para una web corporativa estándar, normalmente tiene baja prioridad.
17. Presencia en skills.sh
Qué es
Este factor analiza si existe una skill o habilidad oficial asociada a la marca en registros específicos de capacidades agentic.
Por qué revisarlo
Las skills pueden facilitar que un agente ejecute tareas concretas o entienda capacidades disponibles.
Cómo medirlo
Se revisa si la marca, dominio o producto aparece en directorios de skills.
Cómo optimizarlo
Solo aplica si la empresa desarrolla una skill, automatización o recurso específico para agentes. La skill debería tener nombre claro, descripción, casos de uso, instrucciones, repositorio o documentación y mantenimiento.
Por qué es importante
Es útil para productos agentic o automatizaciones, pero no es un factor esencial para una web de servicios.
18. pricing.md
Qué es
pricing.md es un archivo de precios legible para máquinas. Su objetivo sería facilitar que agentes y sistemas automatizados entiendan modelos de precio, planes o condiciones comerciales.
Por qué revisarlo
Muchas consultas a IA tienen intención comparativa o comercial. Los usuarios preguntan por precios, planes, costes aproximados o modelos de contratación.
Cómo medirlo
Se comprueba si existe un archivo como /pricing.md o /.well-known/pricing.md, o si hay una página de precios estructurada en la web.
Cómo optimizarlo
En productos SaaS o ecommerce, puede incluir planes, precios, límites y características. En empresas de servicios, puede incluir rangos orientativos, modelos de colaboración, factores que influyen en el presupuesto, tipos de proyecto, qué incluye cada servicio y proceso para solicitar propuesta.
Por qué es importante
Los agentes pueden recomendar mejor una empresa si entienden cómo se contrata y qué referencias económicas existen. Cuando no hay ninguna información, la respuesta suele quedarse en un contacto genérico.
19. NLWeb Schema Feeds
Qué es
Los feeds de schema o recursos estructurados tipo NLWeb buscan facilitar que agentes y sistemas automatizados consulten contenido de una web de forma más organizada.
Por qué revisarlo
Representan una capa avanzada de preparación para IA, especialmente en webs con mucho contenido, catálogos amplios o bases de conocimiento.
Cómo medirlo
Se revisa si la web declara recursos estructurados en archivos técnicos, en el robots.txt o mediante mapas de contenido específicos.
Cómo optimizarlo
Antes de abordar este factor, conviene tener bien resueltos sitemap, datos estructurados, llms.txt, arquitectura interna, contenido semántico, páginas de servicio y FAQs. Después, se pueden crear feeds específicos que organicen el contenido por entidades, temas o tipos de página.
Por qué es importante
Puede facilitar la recuperación semántica de información por parte de agentes. Aun así, es una capa avanzada y no debería priorizarse antes de resolver la base técnica y semántica.
20. Descubrimiento MCP well-known
Qué es
Este factor comprueba si existe una ruta estándar para descubrir un servidor MCP asociado al dominio.
Por qué revisarlo
Si una empresa ofrece herramientas o datos accesibles mediante MCP, los agentes necesitan poder descubrirlos automáticamente.
Cómo medirlo
Se prueban rutas dentro de /.well-known/ y se comprueba si existe información relacionada con MCP.
Cómo optimizarlo
Solo aplica si existe un servidor MCP. En ese caso, debe declararse correctamente, documentarse y enlazarse desde recursos relevantes.
Por qué es importante
Facilita la conexión entre agentes y herramientas externas. Para webs corporativas sin API o sin producto técnico, suele ser no aplicable.
21. Vista específica para agentes
Qué es
Una vista específica para agentes es una versión de la web más limpia, estructurada y pensada para ser leída por sistemas automatizados. Puede ser una ruta específica o una variante de URL, por ejemplo ?mode=agent.
Por qué revisarlo
Una página diseñada para usuarios humanos puede contener mucho ruido visual, componentes interactivos o elementos poco útiles para un agente.
Cómo medirlo
Se comprueba si existe una versión alternativa de la página y si aporta contenido más estructurado que la versión normal.
Cómo optimizarlo
Puede crearse una vista con resumen de la empresa, servicios principales, diferenciales, casos de uso, preguntas frecuentes, enlaces clave, contacto, datos estructurados y formato HTML limpio o Markdown.
Por qué es importante
Facilita que los agentes extraigan información útil de forma rápida y con menos ruido. Es especialmente interesante en webs complejas o muy visuales.
22. Etiquetado visual de contenido
Qué es
Este factor analiza si las imágenes de una web tienen atributos alt descriptivos. El texto alternativo explica el contenido visual a usuarios con lectores de pantalla y a sistemas que no pueden interpretar la imagen directamente.
Por qué revisarlo
Las imágenes también transmiten información. Si no tienen descripción, parte del contenido queda invisible para accesibilidad, buscadores y sistemas automatizados.
Cómo medirlo
Se revisa cuántas imágenes tienen atributo alt y si el texto es realmente útil. No basta con que exista el atributo; debe describir la imagen de forma contextual.
Cómo optimizarlo
Los textos alternativos deben ser claros, naturales y específicos. Las imágenes decorativas pueden tener alt vacío, pero las imágenes informativas deben describirse correctamente.
Por qué es importante
Mejora accesibilidad, SEO de imágenes y comprensión del contenido visual por parte de sistemas de IA.
23. Señales multilingües y hreflang
Qué es
Las señales multilingües indican a buscadores y sistemas automatizados qué versión de una página corresponde a cada idioma o región. La etiqueta hreflang sirve para relacionar URLs equivalentes en diferentes idiomas.
Por qué revisarlo
Una web multilingüe puede generar confusión si no declara correctamente sus versiones. Un sistema podría mostrar la página equivocada o interpretar mal el idioma principal.
Cómo medirlo
Se revisa si las páginas equivalentes tienen etiquetas hreflang, si apuntan a URLs indexables y si existe autorreferencia. También se comprueba que los canonicals no contradigan las etiquetas de idioma.
Cómo optimizarlo
Cada grupo de páginas equivalentes debe enlazarse entre sí mediante hreflang. Por ejemplo, una página en español debería apuntar a su versión en inglés, portugués, francés u otros idiomas, si existen.
Por qué es importante
Ayuda a que usuarios, buscadores y asistentes reciban la versión correcta según idioma o mercado. En IA, reduce el riesgo de respuestas en el idioma equivocado o con URLs incorrectas.
24. Eficiencia de contenido
Qué es
La eficiencia de contenido mide la relación entre texto útil y peso total del HTML. Una página puede tener mucho código, scripts y componentes visuales, pero poco contenido interpretable.
Por qué revisarlo
Los sistemas automatizados procesan mejor páginas con menos ruido técnico y más contenido útil.
Cómo medirlo
Se compara el volumen de texto visible con el tamaño total de la página o del HTML. También se revisan scripts, estilos embebidos, componentes duplicados, HTML innecesario, bloques visuales sin contenido textual o código generado por builders.
Cómo optimizarlo
Se puede mejorar reduciendo código innecesario, optimizando plantillas, simplificando componentes, aumentando contenido útil, eliminando duplicidades y mejorando la estructura semántica.
Por qué es importante
Una web eficiente es más fácil de rastrear, procesar y entender. Para IA, menos ruido técnico puede significar mejor extracción de información.
25. Señales de profundidad de rastreo
Qué es
Este factor analiza si el contenido importante está accesible dentro de la arquitectura de la web o si queda demasiado profundo, aislado o mal enlazado.
Por qué revisarlo
Los sistemas de rastreo priorizan el contenido que está bien conectado y es fácil de encontrar.
Cómo medirlo
Se analiza la profundidad de clics desde la home, el enlazado interno, breadcrumbs, páginas huérfanas, paginaciones, hubs temáticos, menú, footer y relación entre páginas de servicio y contenidos informativos.
Cómo optimizarlo
Las páginas estratégicas deben estar enlazadas desde zonas relevantes de la web. También conviene crear hubs por tema, mejorar breadcrumbs y conectar artículos con servicios relacionados.
Por qué es importante
Una arquitectura clara ayuda a buscadores, usuarios y agentes a entender qué contenido es prioritario y cómo se relacionan las páginas entre sí.
26. HTTP Link headers
Qué es
Los HTTP Link headers son cabeceras que pueden declarar recursos relacionados con una URL, como sitemaps, versiones alternativas, documentación o recursos descriptivos.
Por qué revisarlo
Pueden actuar como señales adicionales para sistemas automatizados. Aunque no son tan habituales en webs corporativas, pueden ayudar en entornos técnicos avanzados.
Cómo medirlo
Se revisan las cabeceras HTTP de respuesta y se buscan valores rel relevantes, como sitemap, describedby, alternate, service-desc o api-catalog.
Cómo optimizarlo
Si tiene sentido técnico, se pueden añadir cabeceras que apunten a recursos importantes, como sitemap, documentación, versiones alternativas o archivos descriptivos.
Por qué es importante
Es una señal avanzada de descubrimiento. Puede facilitar que agentes y sistemas técnicos localicen recursos complementarios sin depender solo del HTML.
27. Fallback Markdown /index.md
Qué es
Este factor revisa si una web ofrece una versión Markdown de una página, normalmente en una ruta como /index.md. Markdown es un formato limpio, estructurado y fácil de procesar por modelos de lenguaje.
Por qué revisarlo
Los agentes pueden interpretar Markdown con menos ruido que HTML complejo.
Cómo medirlo
Se solicita la ruta Markdown y se comprueba si devuelve contenido válido, estructurado y útil.
Cómo optimizarlo
Se pueden crear versiones Markdown para páginas clave: home, servicios, documentación, FAQs, casos de éxito, páginas de metodología y contenidos estratégicos.
Por qué es importante
Facilita la extracción de información por IA y puede mejorar la comprensión en webs con mucho diseño o componentes visuales.
28. llms.txt modular por área
Qué es
Este factor analiza si existen archivos llms.txt específicos para secciones, servicios, productos o áreas temáticas.
Por qué revisarlo
Una web con múltiples servicios puede ser difícil de resumir en un único archivo. Un enfoque modular permite aportar más contexto por área.
Cómo medirlo
Se revisa si existen archivos en rutas asociadas a secciones principales, como /seo/llms.txt, /sem/llms.txt, /analitica-digital/llms.txt o /automatizacion-ia/llms.txt.
Cómo optimizarlo
Cada archivo debería explicar qué es el servicio, a quién va dirigido, qué problemas resuelve, qué metodología se aplica, qué URLs relacionadas existen, qué contenidos conviene consultar y qué preguntas frecuentes resuelve.
Por qué es importante
Mejora la comprensión temática. Los agentes pueden interpretar cada área de negocio con más precisión y recuperar mejor la información relevante.
29. Simulación de rastreo multiagente
Qué es
La simulación de rastreo multiagente analiza si diferentes asistentes o sistemas de IA pueden acceder, procesar y entender una web.
Por qué revisarlo
No todos los agentes se comportan igual. Algunos ejecutan JavaScript, otros no; algunos respetan ciertas directivas, otros tienen limitaciones de contexto o rastreo.
Cómo medirlo
Se prueba el acceso desde distintos tipos de user-agent o entornos de IA y se analiza si el contenido puede ser recuperado correctamente.
Cómo optimizarlo
Para mejorar este punto hay que trabajar accesibilidad del HTML, ausencia de bloqueos técnicos, contenido disponible sin JavaScript, metadatos claros, datos estructurados, llms.txt, arquitectura interna y rendimiento básico.
Por qué es importante
Una web compatible con varios agentes tendrá más posibilidades de ser entendida en diferentes plataformas de IA, no solo en un único ecosistema.
30. Indexabilidad semántica
Qué es
La indexabilidad semántica mide si el contenido puede ser interpretado y recuperado por significado, no solo por palabras clave exactas.
Por qué revisarlo
Una web puede estar optimizada para keywords, pero seguir siendo poco clara para modelos de lenguaje si los contenidos están mal estructurados o son demasiado genéricos.
Cómo medirlo
Se analiza el uso de encabezados descriptivos, organización temática, densidad de contenido útil, claridad de bloques, contexto alrededor de servicios o productos, FAQs, definiciones, enlazado interno contextual y relación entre entidades.
Cómo optimizarlo
Se puede mejorar con páginas específicas por servicio, encabezados claros, FAQs desarrolladas, definiciones de conceptos, ejemplos concretos, contenido por casos de uso, glosarios, enlaces internos semánticos y datos estructurados.
Por qué es importante
La IA no recupera contenido solo por coincidencia exacta de palabras. Una web bien estructurada semánticamente tiene más posibilidades de aparecer en respuestas conversacionales y recomendaciones generadas.
31. Autoridad de marca en datos y fuentes externas
Qué es
Este factor analiza si existen señales externas que ayuden a reconocer una marca como entidad fiable. No se trata solo de lo que la web dice sobre sí misma, sino de cómo aparece la marca en el ecosistema digital.
Por qué revisarlo
Los sistemas de IA pueden apoyarse en múltiples fuentes para entender si una entidad es conocida, fiable o relevante.
Cómo medirlo
Se revisan perfiles corporativos, directorios, reseñas, menciones en medios, entrevistas, colaboraciones, redes profesionales, YouTube, podcasts, publicaciones externas, foros, comunidades y citaciones de terceros.
Cómo optimizarlo
Se puede trabajar mediante PR digital, colaboraciones, contenido experto fuera de la web, casos de éxito publicados, participación en eventos, entrevistas, directorios sectoriales de calidad, reseñas verificables y perfiles sociales consistentes.
Por qué es importante
Una marca con señales externas sólidas tiene más posibilidades de ser reconocida y recomendada por IA. La autoridad no depende únicamente del contenido propio, sino también del reconocimiento en fuentes externas.
32. Context window efficiency
Qué es
La eficiencia en ventana de contexto analiza cuánto espacio necesita un modelo de lenguaje para procesar la información principal de una web.
Por qué revisarlo
Los modelos tienen límites de contexto. Si una web necesita demasiado contenido para explicar lo que hace, un agente puede perder información relevante o interpretar solo una parte.
Cómo medirlo
Se estima el número de tokens necesarios para procesar las páginas principales, el llms.txt, los contenidos clave o la documentación. También se revisa si hay demasiado contenido repetido, ruido o información dispersa.
Cómo optimizarlo
Se puede mejorar con resúmenes claros, llms.txt, llms-full.txt, páginas de servicio bien estructuradas, FAQs, bloques de contenido ordenados, eliminación de duplicidades y jerarquía clara de información.
Por qué es importante
Cuanto más eficiente sea la información, más fácil será para un agente entender la web, responder correctamente y mantener contexto en una conversación.
Para algunas webs, la prioridad estará en mejorar el rastreo, los datos estructurados, el contenido citable y la autoridad. Para otras, especialmente plataformas SaaS, ecommerce avanzados o herramientas digitales, también será necesario revisar APIs, documentación técnica, autenticación, MCP, webhooks y capacidad de acción por agentes.
Por eso, una auditoría IA debe adaptarse siempre al tipo de web y al modelo de negocio. Una web de servicios no necesita los mismos factores que un ecommerce, un medio de comunicación, una web de soporte o una landing de campaña.
La clave está en construir una presencia digital clara para personas y comprensible para sistemas de inteligencia artificial. Las webs que consigan explicar mejor quiénes son, qué ofrecen, por qué son fiables y cómo se puede interactuar con ellas tendrán más opciones de ganar visibilidad en el nuevo escenario de búsqueda conversacional.
Resumen de Factores de descubrimiento, rastreo y comprensión en Auditorias IA para Webs
| Factor | Cuándo analizarlo u optimizarlo |
| Descubrimiento directo de marca en IA | Debe analizarse siempre, especialmente cuando la marca tiene poca presencia externa, puede confundirse con otras entidades o no aparece correctamente al buscar su nombre en buscadores o asistentes de IA. |
| Descubrimiento por caso de uso o intención | Debe analizarse siempre que la web quiera aparecer por necesidades, problemas o servicios, no solo por búsquedas de marca. Es clave en servicios, ecommerce, soporte y contenido. |
| Sitemap XML | Debe analizarse en cualquier web indexable, especialmente si tiene muchas URLs, contenido nuevo frecuente, productos, categorías, artículos o problemas de descubrimiento. |
| Contenido accesible sin JavaScript | Debe analizarse cuando la web usa frameworks, contenido dinámico, builders visuales o carga información mediante scripts. Es crítico si el contenido principal no aparece en el HTML inicial. |
| Accesibilidad para bots y agentes de IA | Debe analizarse siempre, especialmente si hay CDN, firewall, protección antibot, Cloudflare, errores 403/429 o sospecha de bloqueo a rastreadores. |
| Política de IA en robots.txt | Debe analizarse cuando se quiere definir qué bots pueden rastrear la web, si se busca presencia en IA o si hay dudas sobre bloqueo de crawlers de IA. |
| Diferenciación de crawlers de IA | Debe analizarse cuando la empresa quiere permitir ciertos bots y limitar otros, especialmente en medios, ecommerce, webs con contenido sensible o estrategia de protección de datos. |
| Existencia de llms.txt | Debe analizarse cuando se quiere facilitar la comprensión de la web por modelos de lenguaje. Es recomendable en webs de servicios, contenido, ecommerce, soporte y SaaS. |
| Calidad del llms.txt | Debe analizarse si el archivo ya existe o se va a crear, para evitar que sea solo una lista de enlaces y asegurar que aporta contexto real a los modelos de lenguaje. |
| Existencia de llms-full.txt | Debe analizarse en webs con mucho contenido, servicios complejos, documentación extensa, catálogos amplios o necesidad de ofrecer contexto completo en un único recurso. |
| Archivos de instrucciones para agentes | Debe analizarse cuando se quiere orientar a agentes sobre cómo interpretar la web, cuándo recomendarla, qué páginas priorizar o qué información no asumir. |
| Agent discovery file | Debe analizarse en proyectos que quieran facilitar el descubrimiento automático de recursos para agentes, especialmente si ya existen archivos como llms.txt, documentación o capacidades agentic. |
| A2A Agent Card | Debe analizarse solo si la empresa ofrece un agente, herramienta automatizable o servicio agentic que necesite describir capacidades, endpoints o métodos de interacción. |
| Presencia en registros MCP | Debe analizarse en productos técnicos, herramientas SaaS o plataformas que tengan servidor MCP o quieran ser descubiertas por agentes y desarrolladores. |
| Paquetes SDK en NPM o PyPI | Debe analizarse si la empresa ofrece API, librería, producto técnico o herramienta programática que deba ser integrada por desarrolladores. |
| Configuraciones para plataformas de agentes | Debe analizarse en productos técnicos usados por desarrolladores, especialmente si conviene publicar reglas o instrucciones para Cursor, Claude, Windsurf u otros entornos. |
| Presencia en skills.sh | Debe analizarse solo si la empresa desarrolla skills, automatizaciones o capacidades específicas para agentes. En webs corporativas suele ser baja prioridad. |
| pricing.md | Debe analizarse si los usuarios suelen preguntar por precios, planes, tarifas o modelos de contratación. Es importante en ecommerce, SaaS, servicios y productos comparables. |
| NLWeb Schema Feeds | Debe analizarse en webs con mucho contenido estructurable, catálogos, bases de conocimiento o documentación que pueda beneficiarse de feeds semánticos. |
| Descubrimiento MCP well-known | Debe analizarse solo si existe o se plantea un servidor MCP asociado al dominio. En webs sin producto técnico suele ser no aplicable. |
| Vista específica para agentes | Debe analizarse cuando la web es muy visual, pesada, compleja o contiene mucho ruido HTML y se quiere ofrecer una versión más limpia para agentes. |
| Etiquetado visual de contenido | Debe analizarse en cualquier web con imágenes relevantes, especialmente ecommerce, medios, landings y webs visuales donde las imágenes transmiten información. |
| Señales multilingües y hreflang | Debe analizarse cuando la web tiene versiones por idioma o mercado. Es crítico si existen URLs equivalentes en varios idiomas. |
| Eficiencia de contenido | Debe analizarse cuando la web tiene mucho código, scripts, builders, plantillas pesadas o poco texto útil frente al tamaño total del HTML. |
| Señales de profundidad de rastreo | Debe analizarse en webs con muchas URLs, arquitectura compleja, secciones profundas, paginaciones, categorías o sospecha de páginas huérfanas. |
| HTTP Link headers | Debe analizarse en entornos técnicos avanzados, APIs, documentación, recursos alternativos o cuando se quiera declarar relaciones entre recursos desde cabeceras HTTP. |
| Fallback Markdown /index.md | Debe analizarse cuando se quiere ofrecer contenido limpio y fácil de interpretar por modelos de lenguaje, especialmente en documentación, guías o páginas clave. |
| llms.txt modular por área | Debe analizarse cuando la web tiene varias áreas de negocio, servicios, productos o secciones con suficiente entidad como para necesitar contexto propio. |
| Simulación de rastreo multiagente | Debe analizarse cuando se quiere validar cómo interpretan la web distintos asistentes, crawlers o agentes, especialmente si la visibilidad en IA es prioritaria. |
| Indexabilidad semántica | Debe analizarse siempre, especialmente si el contenido es genérico, está mal estructurado, carece de encabezados claros o no cubre bien entidades y relaciones. |
| Autoridad de marca en datos y fuentes externas | Debe analizarse cuando la marca tiene poca presencia externa, pocas menciones, pocas reseñas o necesita reforzar reconocimiento en IA y buscadores. |
| Context window efficiency | Debe analizarse en webs con mucho contenido, duplicidades, textos dispersos o documentación extensa que pueda ser difícil de procesar dentro de una ventana de contexto. |
Factores de Descubrimiento, Rastreo y Comprensión para IA
Factores de Identidad, Confianza y Autoridad para IA
Factores de Integración, automatización y Experiencia agentic para IA.


{kind=link}